
Cómo construir un Loop Engineering con Claude mejor que el 99%
Descubre cómo el Loop Engineering con Claude revoluciona la IA: pasa de escribir prompts a diseñar sistemas que piensan y actúan por sí mismos.
Descubre cómo el Loop Engineering con Claude revoluciona la IA: pasa de escribir prompts a diseñar sistemas que piensan y actúan por sí mismos.

STaR-DRO optimiza la predicción estructurada con LLMs, mejorando el F1 en +14.46 y reduciendo la pérdida grupal. Descubre cómo supera al DRO tradicional.

Descubre cómo los calificadores GenAI evalúan exámenes K-12 con alta precisión en matemáticas y ciencias, aunque escepticismo en notas. Los modelos híbridos reducen la carga docente.

¿La ingeniería de prompts es una habilidad real? Descubre por qué nunca lo fue y qué habilidades realmente importan para usar IA en 2026.

Descubre cómo mantener la consistencia cromática en tus viñetas de manga generadas con IA. Evita la deriva de color con paletas fijas y prompts optimizados.

Descubre cómo BitDive usa IA local para generar tests de regresión a partir de trazas de Java, sin prompts ni costos de tokens. Mantén tus datos privados.

Descubre BitDive: un modelo de IA local que genera tests de regresión a partir de trazas de Java sin enviar datos a la nube. Privacidad y cero costos de tokens.
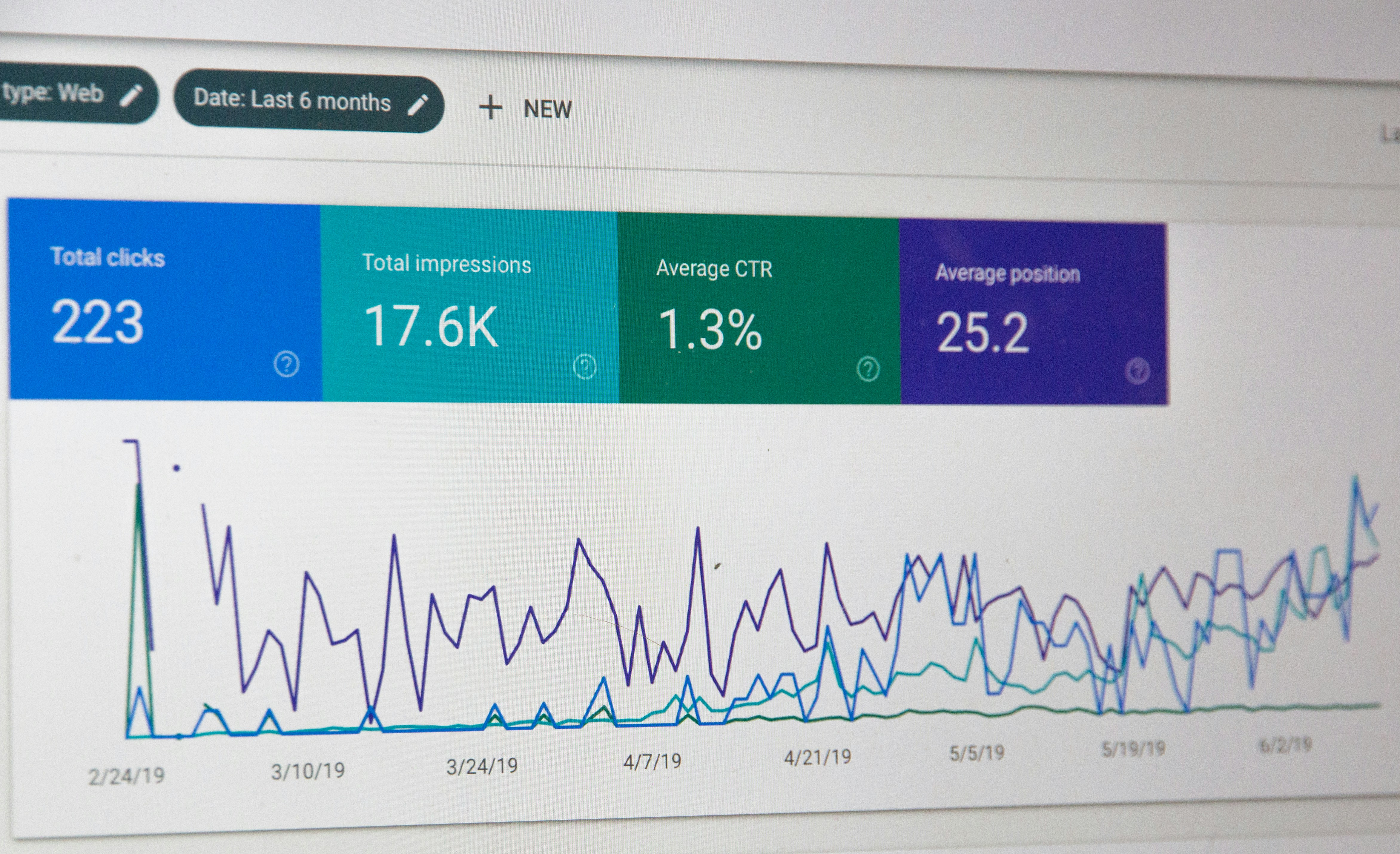
Descubre cómo APEX optimiza prompts con selección dinámica de datos, logrando hasta un 11.2% más de rendimiento en LLMs.

Descubre APEX, un experto en ingeniería automática de prompts que usa selección dinámica de datos para optimizar LLMs, logrando mejoras de hasta 11% en Gemini.
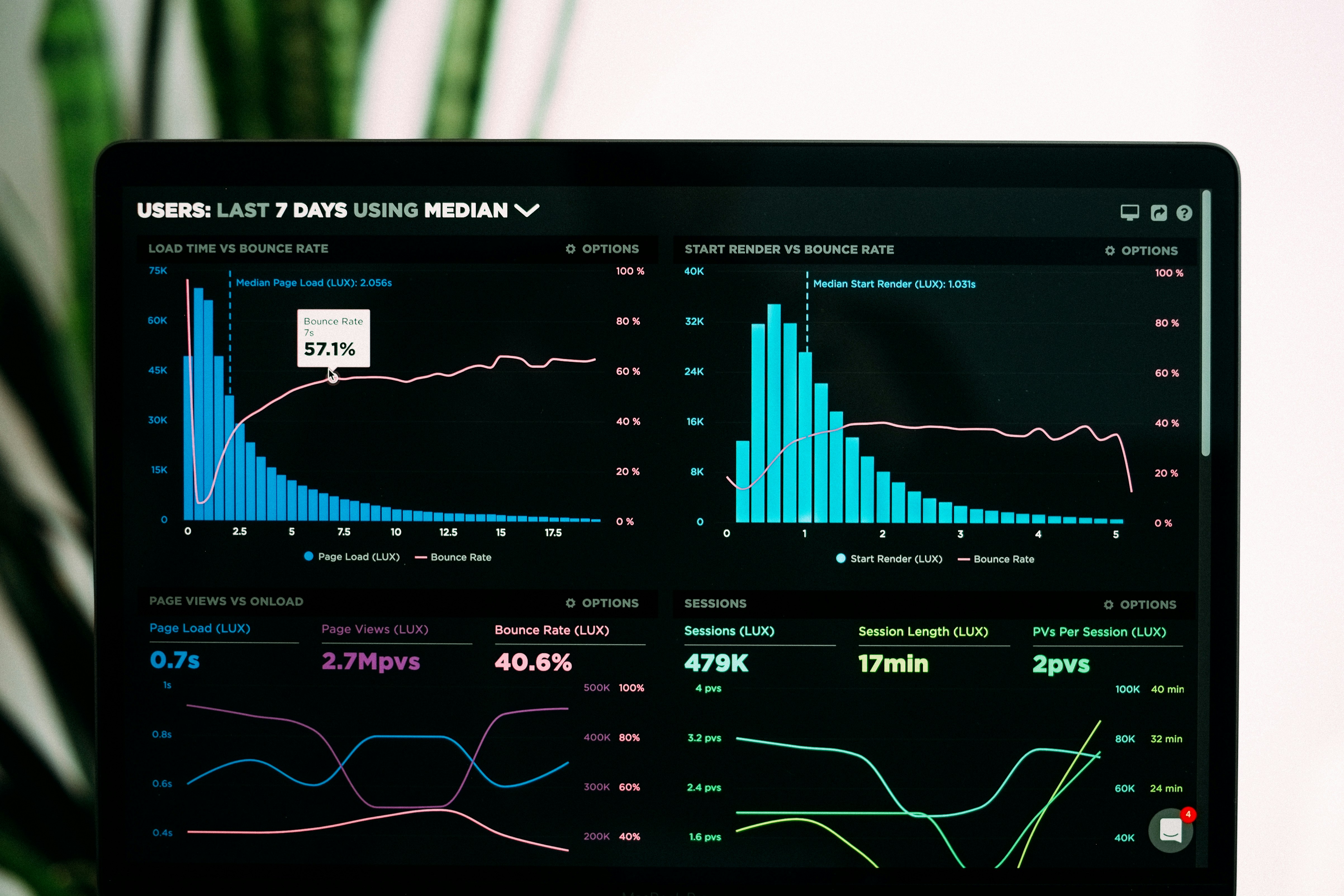
Las mejoras genéricas de prompts pueden empeorar tus aplicaciones LLM. La evaluación iterativa evita regresiones. Resultados con Llama 3 y Qwen 2.5.

Descubre cómo VISTA expone y escapa de la caja negra en la optimización de prompts reflexivos, mejorando la precisión de LLMs en GSM8K y AIME2025.

Evaluamos prompts avanzados en Gemini Flash para QA biomédica. Un prompt complejo logró 0.720, superando al básico (0.565). El diseño de prompts es clave.

La ingeniería de prompts ya no es ventaja competitiva. Descubre por qué la ingeniería de sistemas es la habilidad más valiosa en IA.

SLMs ajustados con zero-shot logran 86.66% de precisión en roles líder-seguidor, superando a prompts. Ideal para computación edge.

SePO optimiza prompts de sistema sin modificar el modelo subyacente. Su enfoque auto-evolutivo mejora la precisión media un 4.49% en cinco benchmarks clave.
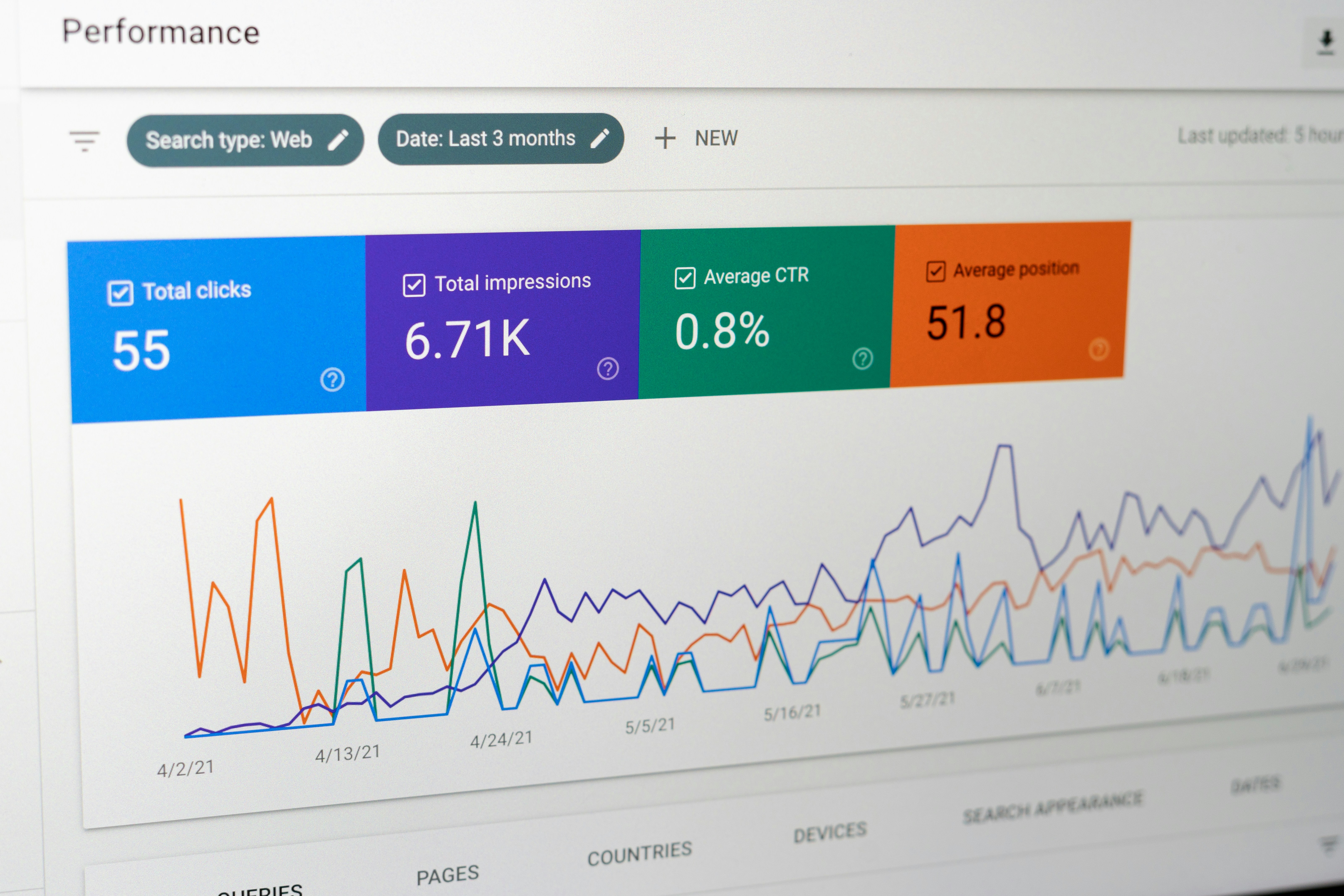
Analizamos 7 sistemas de IA en APIEval-20: desde LLMs hasta agentes de código. Sorprendentes hallazgos sobre detección de bugs y consistencia. ¡Descúbrelo!

Aplica protocolos de evaluación basados en pruebas de aceptación para sistemas LLM seguros, confiables y alineados con el negocio.

Descubre marco optimización prompts que utiliza evaluación unificada para mejorar calidad respuestas por consulta. Resultados interpretables y consistentes.